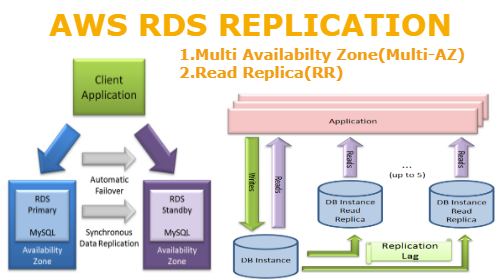
DB Replication 사용 이유
웹사이트 이용 시 select 쿼리가 가장 많이 사용되기 때문에,
read 작업과 write 관련 작업의 서버를 구분해준다면 DB에 부담을 줄여줄 수 있다.
예를들면 write 작업은 Master DB에서 하게 하고, read 작업은 slave DB에서 하게 한다.
select 전용 서버들을 여러 대 구성함으로써 일시적으로 부하시에 분산이 가능하다.
AWS 구성 순서
1. Master DB에서 Replication DB로 복제
2. Route53에서 여러대의 Replication 서버에 트래픽 분산 세팅
3. Laravel 에서 read / write connection 세팅
1. RDS 메뉴에서 Replica 서버 복제

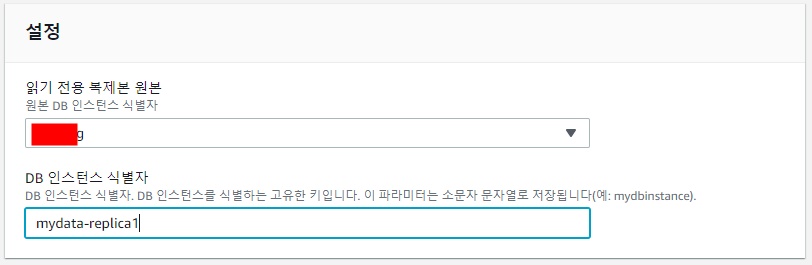
- Master DB를 선택 후 '작업' 드롭다운 메뉴에서 '읽기 전용 복제본 생성' 클릭
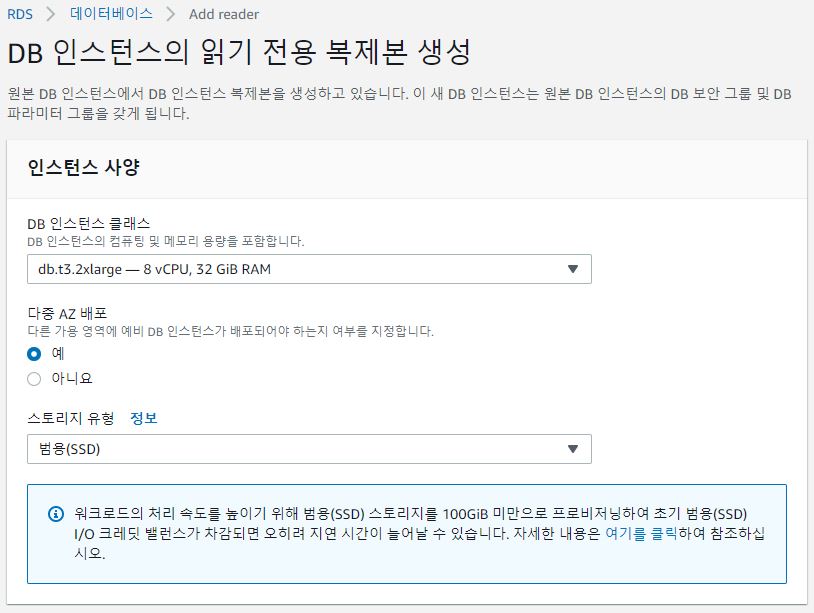

- DB의 스펙을 정하고
- Multi AZ 를 예로 체크
- 퍼블릭 액세스를 예로 체크
- DB 인스턴스 식별자에는 replica의 이름을 기재
- 나머지는 기본으로 두고 확인
2. Route53 작업
- public / private 두 가지의 방식이 있다.
public 으로 세팅하려면 자신의 도메인이 따로 필요하다.
private로 하려면 별도의 도메인은 필요 없다.
여기서는 도메인이 있으므로 public 으로 세팅 해본다.
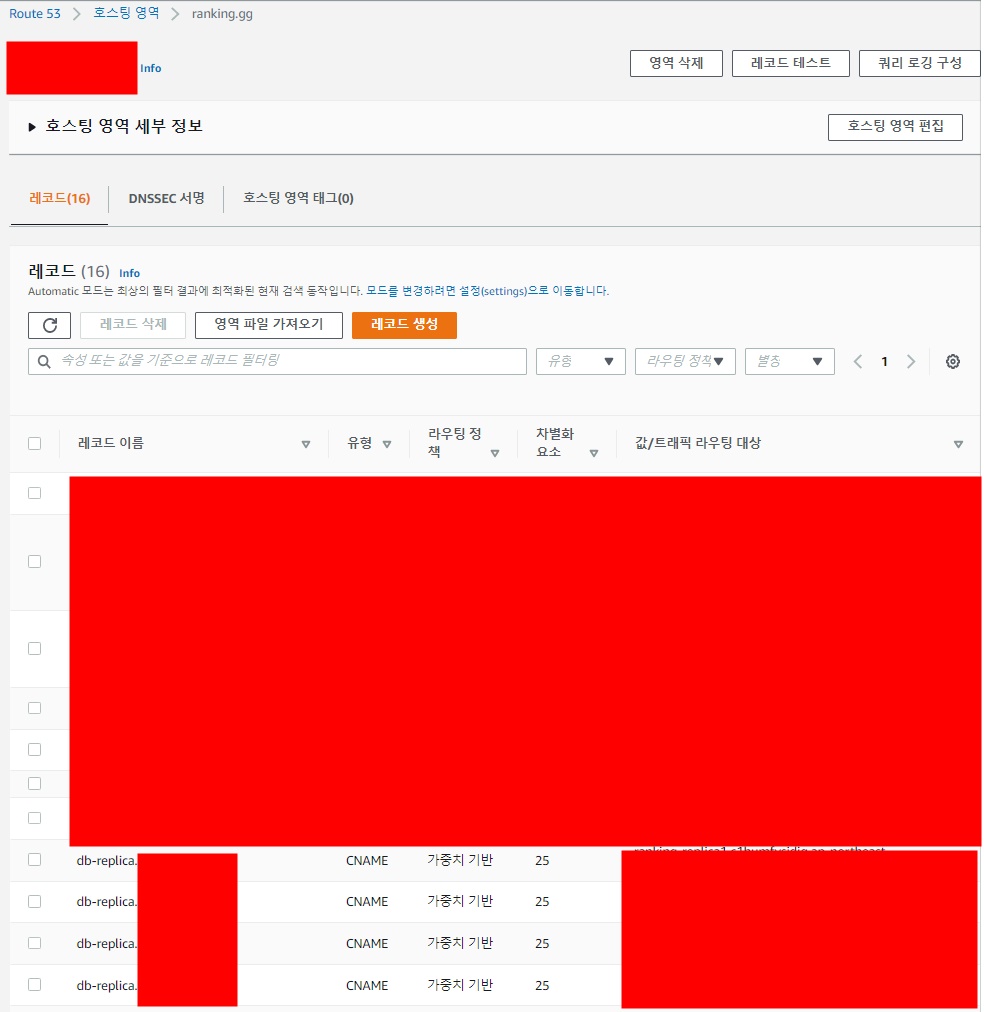
- 레코드 생성
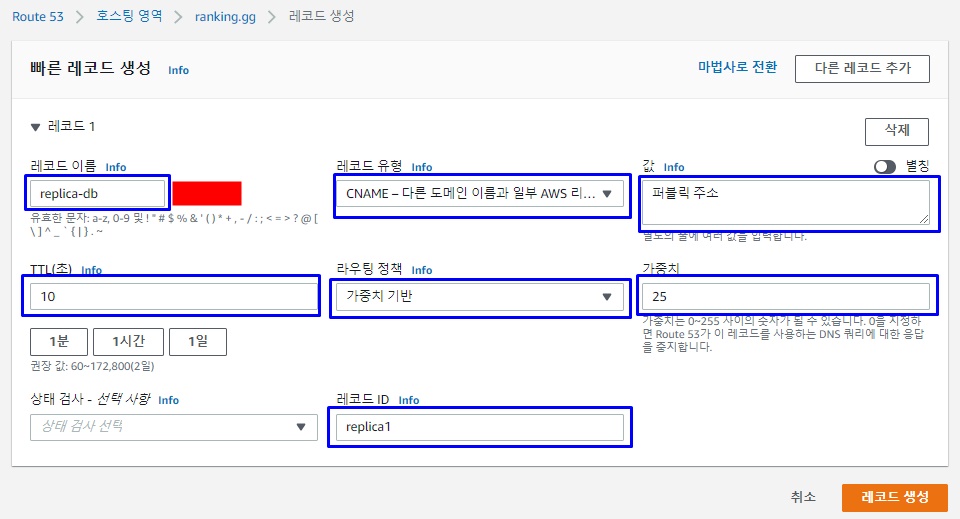
- 레코드 이름 : replica 여러대 모두 같은이름으로 해야 한다. replica들의 접속 endpoint 이다.
- 레코드 유형 : CNAME
- 값 : 아까 만든 replica 의 public 주소를 복사해서 입력한다.
- TTL : 갱신되는 시간이다. 10초정도로 세팅
- 라우팅 정책 : 트래픽이 분산되는 기준이다. 가중치 기반으로 적용
- 가중치 : replica 4대로 구성할 것이므로 각각 25%씩으로 설정
- 레코드 ID : 이름을 정해준다. replica1 / replica2 이런식으로 해주면 됨
- 레코드 생성버튼 클릭
- 위 방법으로 replica 모두 등록해준다 (주의할점 : 레코드 이름은 모두 동일하게 해야 한다.)
3. Laravel 세팅
- config/database.php 파일 수정
'connections' => [
'mysql' => [
'write' => [
'host' => 'master DB 주소 입력'
],
'read' => [
'host' => 'route53에 세팅한 endpoint 주소 입력'
]
]
]- 위처럼 write / read 로 나눠서 세팅해주면 라라벨에서 알아서 분배 해준다.
4. replication 분배 테스트
- 해당 서버에 콘솔로 접속
#> dig replica-db.mydomain.com

- dig 명령어는 nslookup과 비슷한 역할을 한다고 보면 됨
- dig 로 route53에서 세팅한 도메인과 잘 붙었는지 확인
- TTL (10초) 마다 dig 명령어를 확인해보면 랜덤으로 여러 replication 서버가 번갈아가면서 나오면 정상동작 하는것
- ANSWER SECTION에 위 처럼 replica1 과 replica4 가 랜덤으로 접속된다.
'AWS' 카테고리의 다른 글
| 웹 서비스 캐시 다루기 (0) | 2022.10.26 |
|---|---|
| [Cloudflare] AWS S3 보다 저렴한 클라우드플레어 R2 (0) | 2021.11.11 |
| [AWS] crontab을 활용하여 S3로 로그 백업하기 (Elastic Beanstalk) (0) | 2021.03.26 |
| [AWS] AWS CLI를 통해 S3 로 파일 업로드 하기 (0) | 2021.03.24 |
| [AWS] Elastic Beanstalk 콘솔 에서 Laravel 로그 받는 방법 (0) | 2021.03.16 |